De camino al Buffer Overflow (II)
Volvemos en Hacking-Etico.com con esta segunda entrega de «De camino al Buffer Overflow» para abrir el apetito este fin de semana. Se trabajarán en profundidad los conceptos de la primera, disponible en este enlace, con lo cual recomiendo su relectura para no obviar algún detalle que se nos pueda pasar por alto, especialmente información relacionada con los registros ESP y EBP.
Para iniciar la explicación, nos respaldaremos del siguiente código:
int add(int x, int y) {
int sum;
sum = x + y;
return rum;
}
func1() { add(3, 4); }

En este caso, tenemos una función add() que recibe dos enteros por parámetro, define una variable local y retorna un valor. Si fuéramos a analizar el código ensamblador generado por este ejemplo, dentro de la función func1() observaríamos que el primer paso para ejecutar la función add() es colocar los parámetros en la pila ordenados de forma inversa a la lista de parámetros establecida y seguidamente, ejecutar la instrucción CALL.
La instrucción CALL realiza exactamente dos tareas: primeramente almacena en la pila el valor actual del registro EIP (recordamos que significa Extended Instruction Pointer y que es el registro que apunta a la siguiente instrucción a ejecutar) y en segundo lugar, lo modifica para que apunte a la primera instrucción del código de la función. El motivo por el cual se almacena el valor actual del registro EIP es porque una vez se haya finalizado la ejecución de la función add() es necesario saber dónde nos habíamos quedado para poder reemprender des del mismo punto. Una vez ejecutada la instrucción CALL, ya estamos listos para almacenar el valor del registro EBP a la siguiente posición disponible de la pila y modificar su valor para que apunte a ésta. A partir de aquí, se colocarán en la pila las diferentes variables locales de la función paralelamente al progreso de ejecución de su código y también, como se comentó en el primer post, se almacenará información de carácter temporal si es necesario, como por ejemplo valores intermedios de operaciones muy complejas. No obstante, en el ejemplo que nos corresponde sólo se almacenará una variable local que es sum. Todo este procedimiento se encuentra gráficamente representado a la siguiente ilustración:
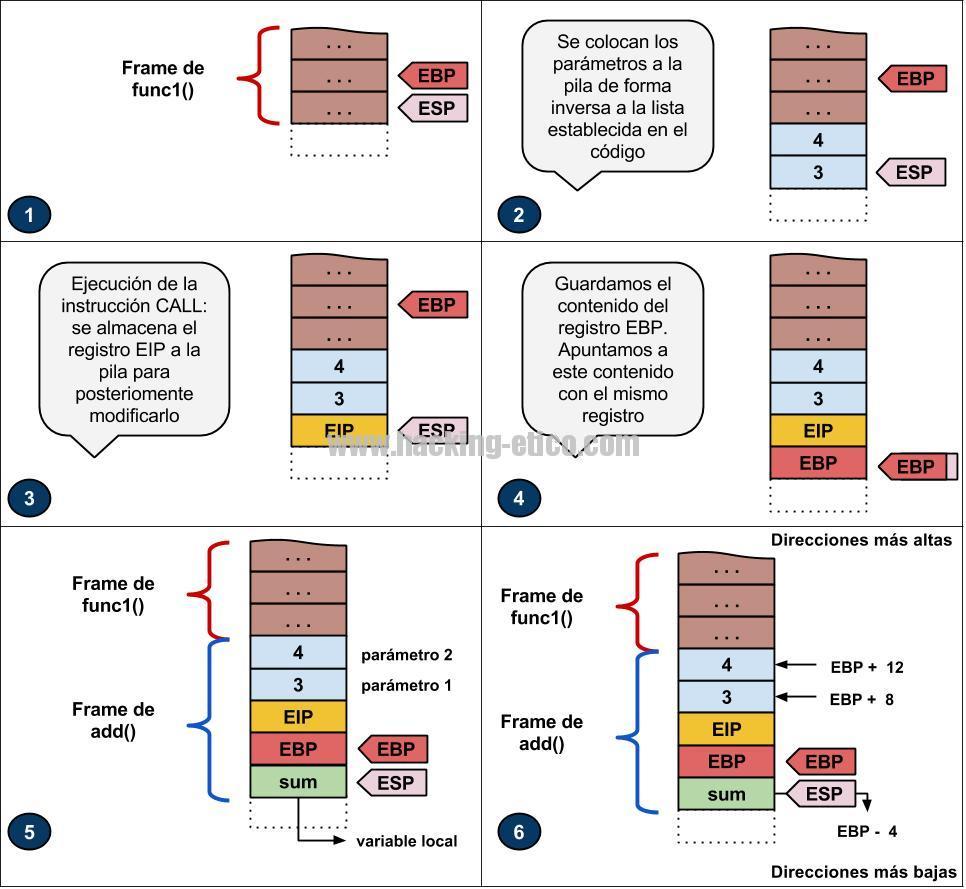
Pues bien, una vez finalizada la ejecución de la función y realizado el cálculo sumatorio quedan dos procedimientos más a efectuar: retornar al mismo punto desde donde se había realizado la llamada y retornar también, si es el caso, el valor de retorno de la función, que en el código del ejemplo es un valor entero contenido por la variable sum.
Vamos por partes. Primeramente, ¿Cuál es el mecanismo que se utiliza para retornar un valor de una función? Como veremos, este mecanismo no es siempre el mismo. Cuando una función retorna un valor de un tipo que ocupa 4 bytes o menos (como en el ejemplo, que se devuelve un int), este valor es almacenado al registro EAX (del Inglés, Extended Accumulator Register, el cual también es usado en las operaciones aritméticas). En cambio, si el valor que se tiene que devolver es de un tipo que ocupa más de 4 bytes (y por lo tanto, no cabe en el registro EAX), entonces se modifica el código de la llamada de la función añadiendo un parámetro adicional: la dirección de memoria en la que el valor de retorno será almacenado. Es decir, para una función de C++ como esta:
obj x = func1(3, 4);
La estructura de la llamada que en realidad se efectuará, suponiendo que el tipo obj ocupa más de 4 bytes, es la siguiente:
func1(&x, 3, 4);
En este caso el valor de retorno será almacenado a la zona de memoria que le pertenece, pero si el valor de retorno es almacenado al registro EAX, el compilador se encargará de añadir el código necesario para que la función a la cual se devuelve (es decir, a la función que ha hecho la llamada) asigne este valor a la variable correspondiente.
En cualquier caso, una vez obtenido el valor de retorno, se tiene que reemprender la ejecución con la siguiente instrucción que se encuentra a continuación de la llamada a la subrutina. Pero, ¿Cómo? ¿Qué es lo que se tiene que hacer para reemprender la ejecución des del mismo punto? Stop here. Paremos a pensar. ¿Lo recordamos?
¡Efectivamente! Todos los registros que queríamos modificar los hemos guardado en la pila antes de proceder, como por ejemplo el registro EIP o el registro EBP. ¡Ahá, sí, ahí está, el registro EIP! Pues parece lógico; El procedimiento a seguir es recuperar todos estos valores almacenados y colocarlos de nuevo a sus registros correspondientes, especialmente el valor del registro EIP. Esto es posible gracias al registro ESP con el cual iremos recorriendo el stack frame de la función actual des de la cima hasta su base con el fin de localizar cada registro almacenado. Vamos a verlo gráficamente:
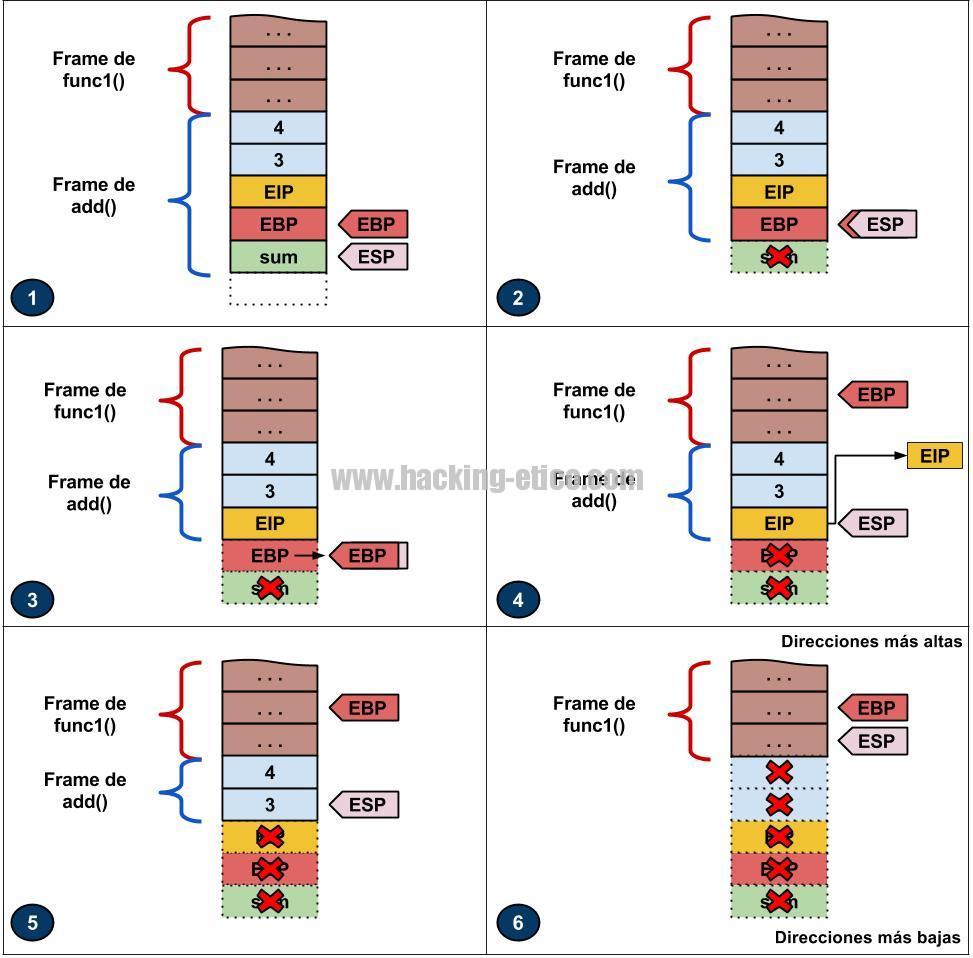
Notamos que en la quinta viñeta se ha recuperado el registro EIP y esto significa que ya se ha cedido el control de la ejecución a la función que ha llamado la subrutina, es decir, que la siguiente instrucción a ejecutar es aquella que se encuentra a continuación de la llamada a la subrutina. No obstante, como podemos ver en la viñeta, aún queda presente en la pila una parte del stack frame de la función add(), la cual corresponde a los argumentos que ha recibido por parámetro. Lo más probable es que estos argumentos no se vayan a utilizar más. En este caso, la función que ha hecho la llamada tiene que encargarse de liberar este espacio ocupado y lo hará simplemente sumando al registro ESP el número de bytes que ocupan los parámetros, es decir, que en el ejemplo anterior sería ejecutar la instrucción ESP + 8, debido a que los parámetros son enteros y ocupan 4 bytes cada uno. De esta forma, se conseguiría la representación de la viñeta número 6.
Intentemos ir un poco más lejos. Pensemos un momento con la siguiente cuestión: ¿Es posible que la función que había realizado la llamada mantuviese unos valores determinados a la multitud de registros de la CPU y que estos hayan sido modificados en la ejecución de la subrutina? Me refiero a registros como el EAX (ya comentado), el ECX (del Inglés, Extended Counter Register) o bien el EDX (del Inglés, Extended Data Register), entre otros. La respuesta, como podemos imaginar, es que sí. Así pues, de nuevo, ¿Cuál es el mecanismo que se utiliza para evitar esta problemática de alteración? Una vez más, la pila es omnipotente. El procedimiento normal, en el caso que sea necesario, es que el compilador escribe las instrucciones necesarias para almacenar el contenido de los diferentes registros a la pila justo antes de que se coloquen los parámetros de la función y por supuesto, también aquellas para recuperar estos valores posteriormente. Este proceso es completamente opcional y solo se realiza para que la subrutina pueda efectuar libremente cambios a los registros y posteriormente puedan ser restaurados con los valores que tenían antes de la llamada a la función.
Llegados a este punto vamos a dar inciso a una característica importante. Ya hemos visto que uno de los rasgos más diferenciales de la pila es que crece hacía las posiciones más bajas de la memoria y esto, en otras palabras, significa que cuando ella va creciendo los valores de los registros (aquellos que apuntan a una posición de memoria que la pila tiene asignada) van disminuyendo, como por ejemplo los registros ESP y EBP. Pero cuidado. Las diferentes zonas que se definen a la pila para almacenar datos (como la zona de parámetros, de variables locales, de valores temporales, etc) se van rellenando ocupando progresivamente el espacio libre en dirección hacia las posiciones más altas de la pila, es decir, ¡En la dirección adversa al crecimiento de la pila! Y aún más. Generalmente se utiliza el formato little-endian para almacenar estos datos, y esto significa que el byte menos significativo se escribe primero. Bueno, pues que lío, ¿no? Tranquilos, la tercera entrega está por llegar ;).
Finalmente, otro aspecto que debo comentar es sobre los documentos técnicos informáticos: todo lo que se ha explicado en este post (y en el anterior, por supuesto) no puede ser interpretado de forma exacta. La idea principal es aproximarse a la realidad de los mecanismos que se utilizan pero la gran variedad de arquitecturas existentes y el rápido progreso de la tecnología hacen que se introduzcan cambios y mejoras constantemente. Un claro ejemplo son los registros del procesador, donde se ha comentado que actualmente se añade una “E” de extended al inicio de su nombre para indicar que tiene un tamaño de 32 bits en lugar de los 16 que tenía anteriormente. ¡Pues esto también ya es obsoleto! La “E” que se utiliza es para referirse a los registros de las arquitecturas de 32 bits, ya que las arquitecturas de 64 bits ya tienen un nombre diferente puesto que se utilizan registros de 64 bits, como el RSP para el registro Stack Pointer.
Otro ejemplo, es que los compiladores reservan espacio adicional en la pila y no de forma estándar, ya que cada compilador y cada versión de él lo hará a su manera. Algunas veces se ve un espacio entre las variables locales y los registros EBP y EIP, pero normalmente no es nada más que una cuestión de alineación de las direcciones de memoria que el compilador gestiona internamente, por ejemplo para que un entero no quede representado en dos porciones de 32 bits y sea necesario trasladar dos palabras (unidad mínima de bits transferidos) en lugar de una para que la CPU acceda a él.
En cualquier caso, resulta imposible representar todos estos detalles sin incrementar la complejidad de la comprensión de los conceptos y por este motivo se opta siempre por realizar representaciones más esquemáticas.
Finalmente, deciros que ya estamos preparados para ver un buffer overflow. Lo analizamos en la siguiente y última entrega.
Ferran Verdés.