SE Hacking Ético: Google Hacking – Parte 4
Volvemos a retomar el tema de Google Hacking. Como ya vimos en SE Hacking Ético: Google Hacking – Parte 1, SE Hacking Ético: Google Hacking – Parte 2 y SE Hacking Ético: Google Hacking – Parte 3 recordamos que Google es el buscador más usado y a la par el más potente de la actual era de Internet. Pero mas allá de escribir direcciones Webs que ya conocemos en el cuadro de texto del buscador (los más newbies en la materia piensan que Google es Internet) tenemos un abanico impresionante de utilidades con Google.
No sólo es un buscador, sino que posee aplicaciones, correo electrónico y hasta smartphones. También posee ciertos comandos «especiales» para precisar muchísimo más en las búsquedas. Comandos muy precisos, para buscar determinados tipos de archivos, rutas, etc…
Estos comandos peculiares forman parte del proceso Footprinting. El cual se basa en la primera fase de todo «Pentest». La obtención de información pública o «Information Gathering«.
Una vez refrescada la memoria un poco, vamos a analizar algunos comandos usados para Google Hacking.

No se compromete nada, ni es una acción ilícita ya que sólo aprovechamos comandos que Google pone a nuestra disposición para su uso.
Podemos diferenciar dos tipos de consultas. Las más comunes o básicas:
– Consulta de palabras.
– Consulta de frases.
– Operadores booleanos: AND, OR, NOT
– Caracteres especiales:
– , + . *
Consultas más avanzadas:
– Intitle, Allintitle
– Inurl, Allinurl
– Allintext
– Site
– Filetype
– Cache
– Numrange
– Daterange
– Link
– Inanchor
– Info
– Related
– Author, Group,
– Insubject, Msgid
– Stocks
– Define
– Phonebook
Con el uso de estas «claves» para concretar búsquedas podemos llegar muy fácilmente a directorios que no deberían estar indexados en Google. Por ejemplo:
intitle:index of passwd
Obtenemos algo parecido a esto:

Otro ejemplo buscando directorios del usuario «admin» los cuales no se deberían mostrar ya que se supone que es de acceso a un único usuario y para colmo, usuario administrador. Si usamos el comando:
intitle:index.of inurl:admin
Obtendremos los siguientes resultados:
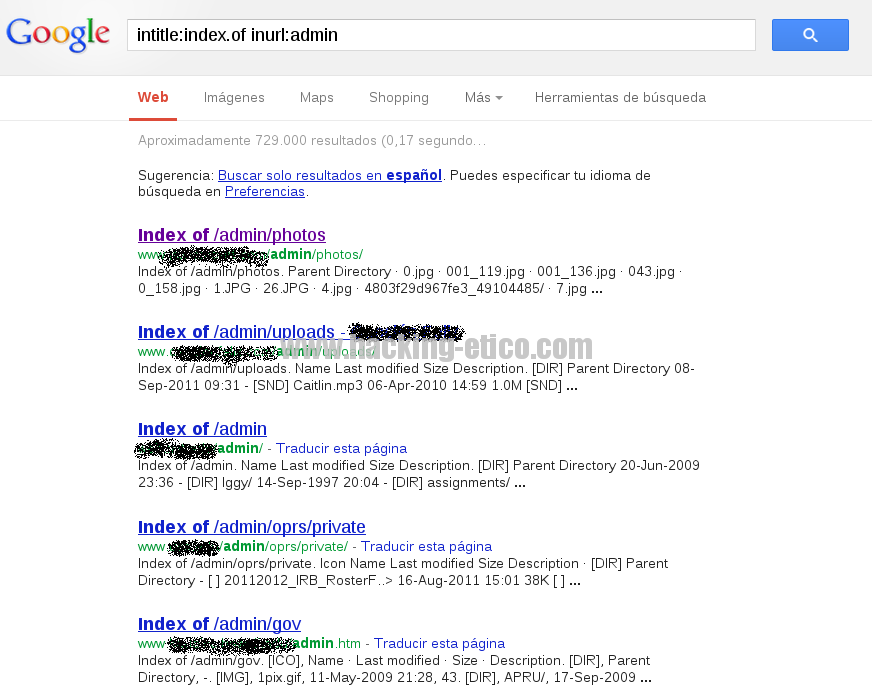
Como podéis observar los comandos pueden recolectar información muy interesante a la hora de iniciar un proceso de Pentesting. Hay muchos más comandos, a continuación listamos unos pocos de ellos:
intitle:index.of “parent directory”
intitle:index.of inurl:admin
intitle:index.of ws_ftp.log
intitle:index.of “Apache/*” “server at”
intitle:index.of “Microsoft-IIS/* server at”
site:sitio.com -site:www.sitio.com
Nombres de usuario:
“acces denied for user” “using password»Estructura de la base de datos:
filetype:sql “# dumping data for table”
Inyección de SQL:
“Unclosed quotation mark before the character string”Código fuente SQL
intitle:»Error Occurred» «The error occurred in” “incorrect syntax near”
Contraseñas
filetype:inc intext:mysql_connect filetype:sql «identified by» -cvs
Detección de archivos en base de datos:
filetype:mdb inurl:users.mdb filetype:mdb inurl:email inurl:backup
Hemos de decir que existen programas que implementan estos comandos en interfaces gráficas mas intuitivas, complementado con los comandos. Unas utilizan la API de Google por lo que están mas limitadas respecto al número de peticiones, y otras no, las cuales no violan los términos de uso de Google.
«Wikto» es una de ellas y usa la API de Google. En cambio «Athena» no la usa.
Pero bueno, ¿Cómo protejo mi servidor Web de tal indexación?
Pues creando un fichero txt, concretamente uno llamado robots.txt conteniendo las siguientes premisas:
User-agent: googlebot
Disallow: /directorio/archivos
Para que no indexe nuestro sitio no estaría de sobra añadir este código para evitar la indexación:
<META NAME=»GOOGLEBOT» CONTENT=»NOINDEX, NOFOLLOW»>
Para no almacenar en caché:
<META NAME=“GOOGLEBOT” CONTENT=“NOARCHIVE”><META NAME=“GOOGLEBOT” CONTENT=“NOSNIPPET”>
Y por último sino queremos que nuestro sitio permanezca en la caché de google porque ya lo hemos eliminado o simplemente no queremos, podemos acceder a la siguiente URL para anularlo.
services.google.com/urlconsole/controller
Apuntamos al archivo robots.txt, utilizar una directiva META y elegimos la opción de eliminación de enlaces antiguos.
Estos comandos, son potentísimos a la par que peligrosos en potencia. Hace poco tiempo salió una noticia en la que Google indexaba 86.000 impresoras. Basta con entrar el siguiente comando para obtener el listado.
inurl:hp/device/this.LCDispatcher?nav=hp.Print
Con el listado podremos obtener multitud de datos para una presunta fase inicial de ataque (Information Gathering). Por ello no es nada aconsejable tener una impresora de red indexada de esta forma.
Saludos no-indexados!!