Skipfish, Escaner Web
Hoy en día existen infinidad de aplicaciones, scripts, frameworks, etcétera para auditar sistemas, ya sean de infraestructura de red, Web, Web basado en OWASP, Wireless, etc… Suelen aparecer software con versiones gratuitas, gratuitas con limitaciones y versiones de pago con diferentes de modalidades.
Las de pago las vamos a obviar porque evidentemente, se necesita una inversión bastante potente en muchas de ellas y para algo “casero” pues no es demasiado lógico gastarse miles de euros.
Las versiones libres o scripts subidos a la red (GitHub por ejemplo), suelen tener la ventaja que son personalizables y puedes editarlos a tu gusto, que es lo que se estila para adaptar los resultados a gusto o necesidad de auditores o meros curiosos.
Hoy nos vamos a centrar en mostrar un escaner Web bastante potente que tiene sus pros y contras pero que es otra herramienta más que puede ayudarnos enormemente en labores de buscar agujeros de seguridad en plataformas Web ya sean en pre-producción o producción. Hablamos de Skipfish

Skipfish tiene sus añitos ya pero últimamente he experimentado con ella(la app) más sobre entornos controlados montados por mí para ver el potencial que tiene tanto el nivel de “intrusividad” (ruido) como los resultados que realmente es lo que importa (¿no? xD)
Si ejecutamos el comando de ayuda nos mostrará un listado de parámetros que, dependiendo el entorno, pueden sernos más o menos útiles.
root@kali-kmx:~# skipfish -h
skipfish web application scanner – version 2.10b
Usage: skipfish [ options … ] -W wordlist -o output_dir start_url [ start_url2 … ]Authentication and access options:
-A user:pass – use specified HTTP authentication credentials
-F host=IP – pretend that ‘host’ resolves to ‘IP’
-C name=val – append a custom cookie to all requests
-H name=val – append a custom HTTP header to all requests
-b (i|f|p) – use headers consistent with MSIE / Firefox / iPhone
-N – do not accept any new cookies
–auth-form url – form authentication URL
–auth-user user – form authentication user
–auth-pass pass – form authentication password
–auth-verify-url – URL for in-session detectionCrawl scope options:
-d max_depth – maximum crawl tree depth (16)
-c max_child – maximum children to index per node (512)
-x max_desc – maximum descendants to index per branch (8192)
-r r_limit – max total number of requests to send (100000000)
-p crawl% – node and link crawl probability (100%)
-q hex – repeat probabilistic scan with given seed
-I string – only follow URLs matching ‘string’
-X string – exclude URLs matching ‘string’
-K string – do not fuzz parameters named ‘string’
-D domain – crawl cross-site links to another domain
-B domain – trust, but do not crawl, another domain
-Z – do not descend into 5xx locations
-O – do not submit any forms
-P – do not parse HTML, etc, to find new linksReporting options:
-o dir – write output to specified directory (required)
-M – log warnings about mixed content / non-SSL passwords
-E – log all HTTP/1.0 / HTTP/1.1 caching intent mismatches
-U – log all external URLs and e-mails seen
-Q – completely suppress duplicate nodes in reports
-u – be quiet, disable realtime progress stats
-v – enable runtime logging (to stderr)Dictionary management options:
-W wordlist – use a specified read-write wordlist (required)
-S wordlist – load a supplemental read-only wordlist
-L – do not auto-learn new keywords for the site
-Y – do not fuzz extensions in directory brute-force
-R age – purge words hit more than ‘age’ scans ago
-T name=val – add new form auto-fill rule
-G max_guess – maximum number of keyword guesses to keep (256)-z sigfile – load signatures from this file
Performance settings:
-g max_conn – max simultaneous TCP connections, global (40)
-m host_conn – max simultaneous connections, per target IP (10)
-f max_fail – max number of consecutive HTTP errors (100)
-t req_tmout – total request response timeout (20 s)
-w rw_tmout – individual network I/O timeout (10 s)
-i idle_tmout – timeout on idle HTTP connections (10 s)
-s s_limit – response size limit (400000 B)
-e – do not keep binary responses for reportingOther settings:
-l max_req – max requests per second (0.000000)
-k duration – stop scanning after the given duration h:m:s
–config file – load the specified configuration fileSend comments and complaints to <[email protected]>.
Lo mejor para mostrar alguna de utilidad de este tipo es hacer la PoC (Proof of concept) sobre algún sitio Web, para ver qué resultados nos muestra.
El sitio utilizado es un sitio propio, que contiene un formulario de login y, por tanto, obviaremos que NO tenemos credenciales de acceso para ver que nos muestra.
Lanzaremos así:
skipfish -o hacking-etico URL
Dónde “-o” es opción de reporting, seguido del nombre que queremos darle al directorio cuando finalce las pruebas y continuando con la URL. Aparecerán resultados tapados para que cuando estéis aburridos no os dediquéis a reventarme la Web, aunque sea de pruebas 😛
Aquí vemos una pantalla de bienvenida, la cual muestra algunas instrucciones interesantes por si queremos usar en Skipfish.
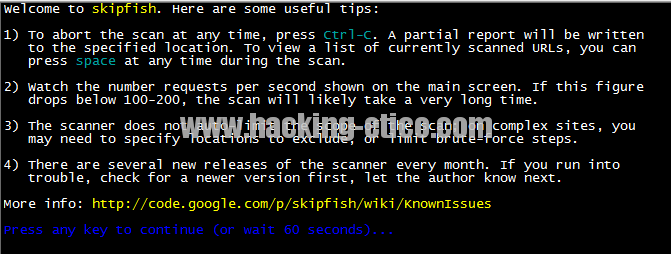
Sino le damos a ninguna tecla, en 60 segundos continuará con el scan. Al finalizar mostrará algo como esto:
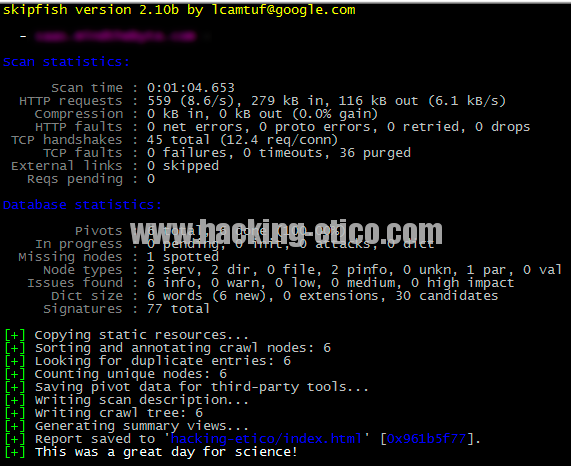
Al ser un sitio bastante limitado y sin tener una estructura enorme, el resultado es bastante rápido y el análisis arroja muy poca información.
Para sitios más extensos o si solamente queremos hacer una pequeña prueba podemos usar el parámetro “-k” para darle un límite de tiempo de ejecución. Por ejemplo, aquí le estamos diciendo que solamente queremos que esté 5 minutos analizando y luego se pare y genere el informe.
![]()
Recordad que siempre al final poner la URL que en nuestro caso estamos difuminando para evitar que sea utilizada por “curiosos” para saciar sus ganas de aprender xD.
Aquí veremos otro resultado con la limitación de 5min a otro sitio Web propio, mucho más completo.
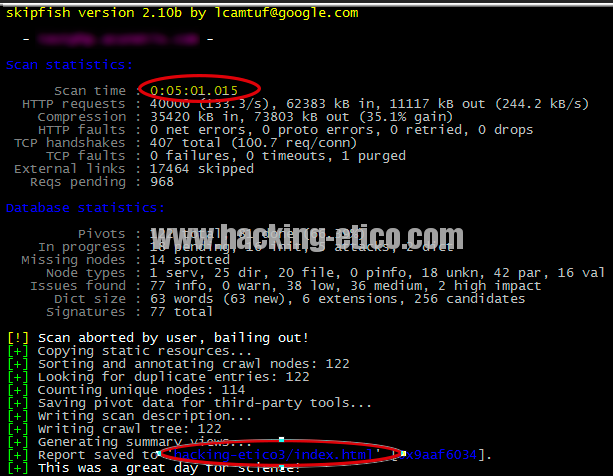
Ahora, vamos a ver como muestra el resultado en HTML. Como veis en la anterior captura, hemos marcado dos ítems, uno el del tiempo y otro el directorio dónde guarda ficheros para generar el informe, este en HTML.
Veamos la estructura que realiza Skipfish cuando realizamos un scan:
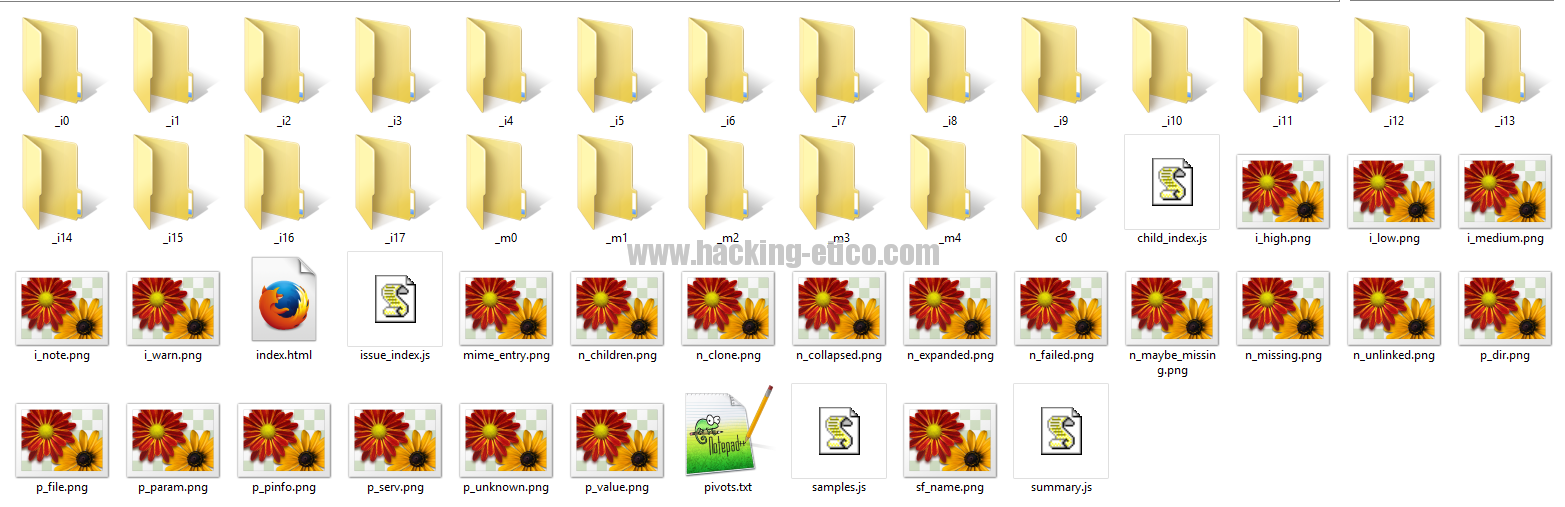
Cuando clicamos en el fichero index.html obtendremos una pantalla similar a esta: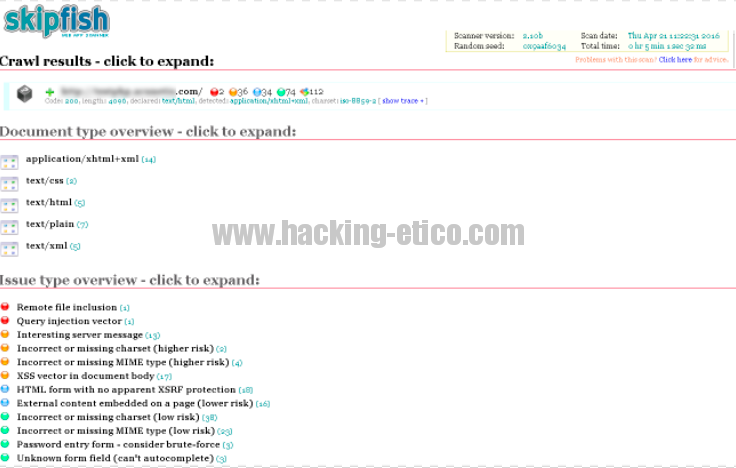
Si clicamos en alguno de los ítems (los colores más cálidos, son issues de más riesgo) nos mostrará las URLs supuestamente vulnerables. Y digo supuestamente vulnerables porque no siempre los resultados, ya sea de cualquier escáner automático, van a ser 100% positivos. Lo que se conoce como “falsos positivos”.
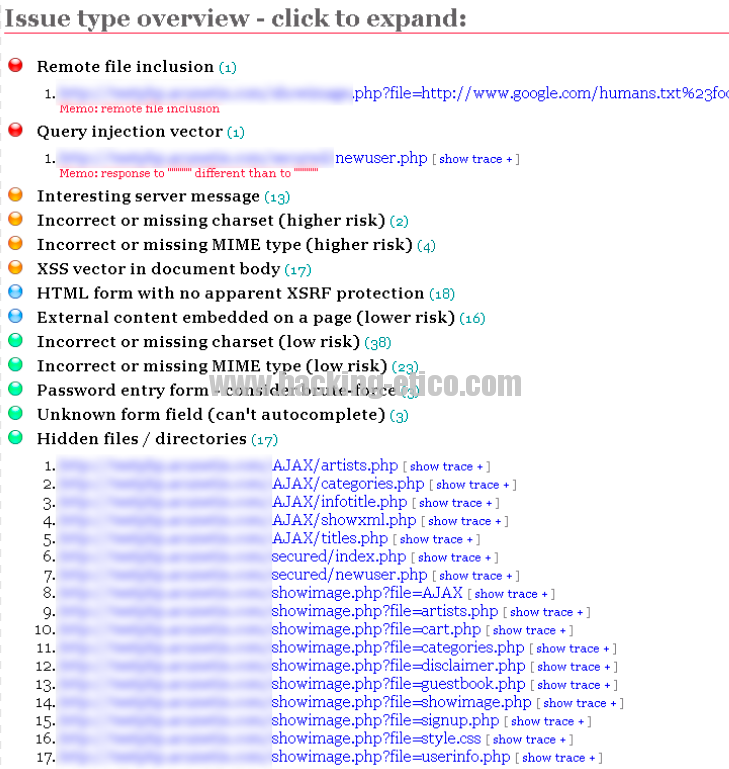
Aquí dónde entra el valor de cada auditor, ya que esto la única forma de comprobarlo es a «manopla» por lo que es imprescindible unos conocimientos importantes para conocer los entresijos de la seguridad Web como se ven en nuestro Curso de Hacking Ético Web que encima es basado en OWASP, toma ya! xD
Otra cosa importante a aclarar, es que esto nos debe servir únicamente de apoyo para una auditoría ya que esto no es infalible y lo mejor es complementarlo con otras apps, scripts y el propio conocimiento del auditor que es, obviamente, lo más importante. No obstante para personas poco duchas en la materia, es una forma de empezar a mirar sus sitios Webs.
En resumidas cuentas, con esto podemos realizar auditorías básicas de nuestros sitios Webs para comprobar si nos hemos dejado algo en el tintero, ya sea código mal “picao” o directorios o ficheros que no tienen por qué estar indexados. No obstante, como mejor podéis comprobarlo es contra algún sitio Web propio (siempre de vuestra propiedad, muy importante, sino podéis estar incurriendo en un delito) y si la montáis en una VM mejor, que así evitáis cualquier tipo de medida de seguridad que pudiera tener el host. Obtendréis así un estado más “puro” de la seguridad de vuestro código Web.
Se me olvidaba, esta app viene de serie en Kali Linux 2.0 por lo que ni tendréis que instalarla.
Espero que os sea de utilidad!
@ManoloGaritmo